
In the age of Large Language Models (LLMs), the reality of intelligent, context-aware AI systems has never been closer. Yet, many extremely advanced models like GPT-5 or the Claude 4 series face a fundamental limitation. It is that they can only generate text based on what they were trained on.
What happens when you need the model to answer questions about your private company data, recent events, or domain-specific documents?
This is where RAG enters the picture, a hybrid approach that brings real-time knowledge into generative reasoning.
What is RAG?
Retrieval-Augmented Generation (RAG) is an architecture that combines information retrieval with language generation.
Instead of relying solely on a model’s static internal knowledge, RAG dynamically retrieves relevant documents or snippets from an external knowledge base (like vector stores or document databases) and uses them to augment the model’s prompt before generating a response.
At a high level, RAG = Retriever + Generator.
How RAG Works: Step-by-Step
Let’s break down the RAG pipeline into its core components:
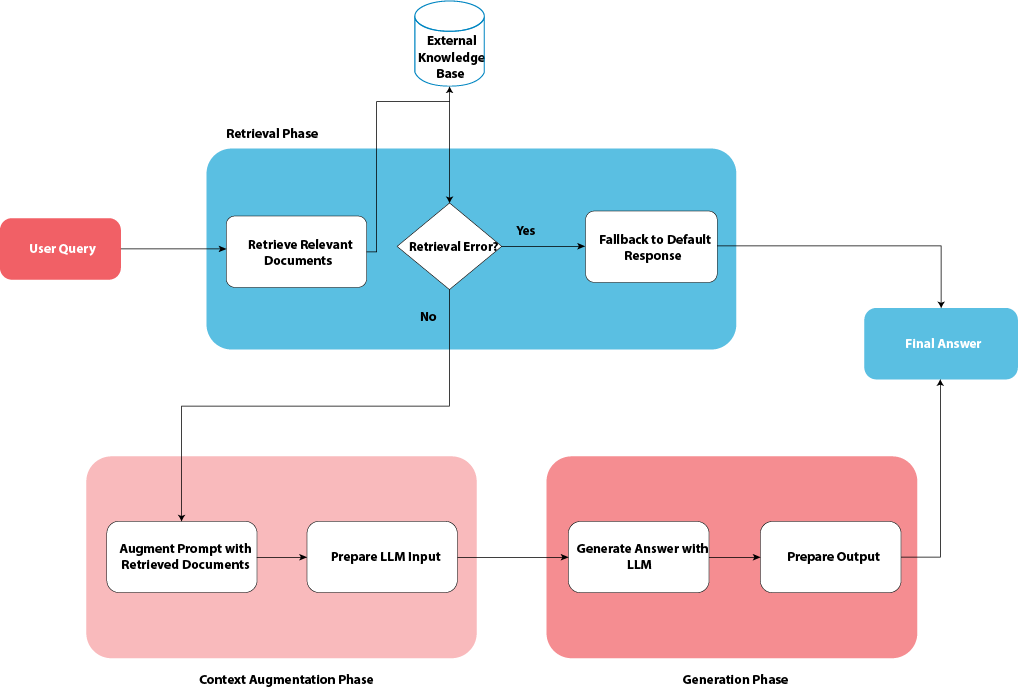
1. Input Query
A user submits a question or request, for example:
“Explain how RAG works in a production-grade chatbot.”
2. Document Retrieval
The system retrieves relevant data from an external source, typically a vector database (like Pinecone, Chroma, FAISS, Weaviate, or OpenSearch).
Documents are represented as embeddings – numerical vectors that encode semantic meaning.
The retriever uses similarity search (for example, cosine similarity) to find documents most related to the query.
For instance:
- Retrieved Document 1: “RAG combines retrieval with generation for factual accuracy.”
- Retrieved Document 2: “Vector embeddings allow semantic search over large datasets.”
3. Context Augmentation
The retrieved documents are injected into the LLM prompt.
This augmented context looks something like:
Context:
Document 1: RAG combines retrieval with generation for factual accuracy.
Document 2: Vector embeddings allow semantic search over large datasets.
User Query:
Explain how RAG works in a production-grade chatbot.
4. Generation
The LLM (such as GPT, Claude, or LlaMa) analyses the context and generates an informed answer, grounding its response in the retrieved documents.
5. Post-Processing (Optional)
Responses may be refined, summarized, or verified using:
- Citation generation
- Fact-checking modules
- Confidence scoring
Why Use RAG Instead of Fine-Tuning?
| Aspect | Fine-Tuning | RAG |
|---|---|---|
| Data Updates | Requires retraining for new knowledge | Dynamic retrieval – instant updates |
| Storage | Expensive (stores weights for each version) | Lightweight (stores documents in DB) |
| Explainability | Opaque model decisions | Transparent (shows which docs were used) |
| Cost | High compute/training cost | Lower runtime retrieval cost |
| Use Case | Domain adaptation (e.g., medical writing style) | Knowledge augmentation (e.g., enterprise Q&A) |
In short:
- Fine-tuning teaches the model how to think in a domain.
- RAG tells the model what to think about using external data.
Best Practices for Production RAG Systems
- Use high-quality chunking
- Split documents semantically (e.g., by heading or paragraph) rather than fixed token length.
- Optimize embeddings
- Choose embedding models suited for your language and domain (e.g., text-embedding-3-large for multilingual data).
- Implement caching
- Cache retrievals and generations for frequent queries to save cost and improve latency.
- Cite sources
- Always return document references or confidence scores for transparency.
- Guard against hallucinations
- Use guardrails, retrieval filters, or grounding checks to ensure model output only references retrieved data.
RAG in Real-World Applications
RAG isn’t just a research idea; it’s production-critical in many systems:
- Enterprise Chatbots: Access internal documentation securely
- Healthcare AI: Provide grounded answers using validated research
- Financial Analysis: Retrieve the latest market data before reasoning
- Code Assistants: Search project files before suggesting code
Major AI giants like OpenAI, Anthropic, and AWS (via Bedrock) have already integrated RAG-based pipelines in their enterprise offerings.
Conclusion
Retrieval-Augmented Generation represents a new frontier for AI, one where LLMs are no longer static models, but dynamic, knowledge-aware systems.
By bridging retrieval and reasoning, RAG allows organizations to:
- Keep AI systems up-to-date
- Improve factual grounding
- Build trustworthy, explainable intelligent assistants
In essence, RAG transforms large language models from generative storytellers into knowledge-driven problem solvers.
